©Sergey Nivens – stock.adobe.com
Generative KI für wissenschaftliche Erkenntnisse
Forschungsvergleiche mit ChatGPT
Jetzt ist also die Zeit der generativen KI angebrochen – mit ihren großen Sprachmodellen (englisch: Large Language Models, kurz LLM) wie ChatGPT, das auf dem LLM GPT-3.5 mit 6,7 Milliarden Parametern basiert. Informatiker hatten zwar erwartet, dass das Skalieren von Sprachmodellen ihre Leistung bei bereits bekannten Aufgaben steigern würde, aber nicht, dass die Modelle plötzlich so viel Neues und Unvorhersehbares meistern können. Tatsächlich erscheinen täglich neue ChatGPT-Nutzungsszenarien in Blogs und Tweets. Dieses Phänomen, Emergenz genannt, tritt auf, wenn aus Wechselwirkungen innerhalb eines Systems neue komplexe Eigenschaften oder Verhaltensweisen entstehen. Emergenz ist in der Informatik heute eine zentrale Forschungsfrage; in der Biologie, Physik oder Kunst wird sie schon seit langem diskutiert. „Soweit ich weiß, wurde in der Literatur nie beschrieben, dass Sprachmodelle diese Arten von Aufgaben übernehmen können“, sagt Rishi Bommasani, Informatiker an der Stanford University. Im vergangenen Jahr half er, eine Liste dutzender emergenter Verhaltensweisen zusammenzustellen. Auch das von Ethan Dyer (Google Research) initiierte Projekt Beyond the Imitation Game Benchmark (BIG-bench) dokumentiert aufkommende Verhaltensweisen von LLMs. 444 Autoren aus 132 Institutionen haben dazu 204 Aufgaben beigesteuert. Die Themen sind vielfältig und umfassen Problemstellungen unter anderem aus den Bereichen Linguistik, kindliche Entwicklung, Mathematik, Biologie, Physik oder Softwareentwicklung.
Im Joint Lab von L3S und TIB befassen sich Dr. Jennifer D’Souza und ihr Team mit der Entwicklung und Nutzung von LLMs im Projekt Open Research Knowledge Graph (ORKG). Der ORKG nutzt semantische Technologien für den Austausch von Forschungswissen in neuer Form statt in PDF-Dokumenten. Das zentrale Element sind Forschungsvergleiche. Sie funktionieren ähnlich wie Amazon-Produktvergleiche, nur dass ORKG-Forschungsvergleiche auf strukturierten, eigenschaftsbasierten Beschreibungen von Forschungsbeiträgen basieren. „Mit dem Open Research Knowledge Graph erfinden wir die wissenschaftliche Kommunikation neu“, sagt Projektleiter Prof. Dr. Sören Auer.
Wie gut ist ChatGPT im Vergleichen von Forschungsbeiträgen? Die Wissenschaftler haben den Chatbot aufgefordert, für drei Artikel einen Forschungsvergleich anhand ihrer Titel und Zusammenfassungen zu erstellen (Create a comparison table from the given text of the following three papers). Das Ergebnis: „Ein guter erster Versuch“, sagt D´Souza.
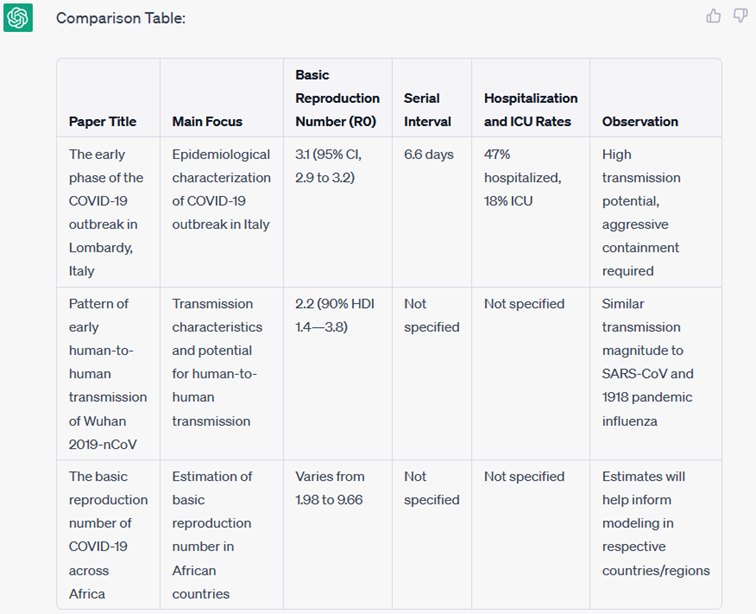
Abb. 1: ChatGPT generiert einen Forschungsvergleich
Allerdings sollte sich ein ORKG-Forschungsvergleich auf ein gemeinsames Forschungsproblem stützen, in diesem Fall die Covid-19-Basisreproduktionszahl (R0). Um einen schlüssigen Überblick über den Beitrag zu erhalten, müssen der Zahl R0 weitere Eigenschaften gegenübergestellt werden. Der obige Vergleich hat aber nur eine Eigenschaft korrekt wiedergegeben: den Wert von R0. Die Wissenschaftler forderten ChatGPT erneut auf, einen Forschungsvergleich zu erstellen, aber diesmal mit den gewünschten Eigenschaften (Create a comparison table from the given text of the following three papers based on the following properties: location, date, R0 value, % CI values, and method).

Abb. 2: ChatGPT generiert einen Forschungsvergleich bei gegebenen Eigenschaften
Bingo! Das Ergebnis (Abb. 2) ist ein Forschungsvergleich, der zu etwa 80 Prozent korrekt ist und keine Halluzinationen aufweist − ein Phänomen, bei dem LLMs Informationen erfinden. Dass LLMs Tabellen erzeugen, ist ein eher überraschender Befund, der deutlich vom erwarteten Verhalten bei der Texterzeugung abweicht.
Im Projekt ORKG forscht das Team aktiv am Einsatz von LLMs als Assistenten für die Generierung von Forschungsvergleichen. Der Artikel zeigt ein positives Beispiel, jedoch gibt es auch Fälle, in denen das Modell angesichts längerer oder unzureichender Kontexte versagte oder sogar Informationen halluzinierte. „In den nächsten Monaten wollen wir die Fähigkeit der LLMs zur Erstellung von Forschungsvergleichen messen und hoffen, einen Beitrag zur Liste der emergenten Aufgaben in BIG-Bench leisten zu können“, sagt D´Souza.
Vorgestellte Projekte

Kontakt

Dr. Jennifer D‘Souza
Jennifer D'Souza ist Postdoktorandin im Projekt Open Research Knowledge Graph in der Gruppe Datenwissenschaft und Digitale Bibliotheken an der TIB. Sie forscht auf den Gebieten der Verarbeitung natürlicher Sprache und des Semantic Web.

Prof. Dr. Sören Auer
Sören Auer ist Mitglied des erweiterten L3S-Direktoriums, Direktor der TIB – Leibniz-Informationszentrum Technik und Naturwissenschaften und Professor für Data Science und Digital Libraries an der LUH.